多模态大模型训练的显存与吞吐困局,被小红书开源的BigMac打破了
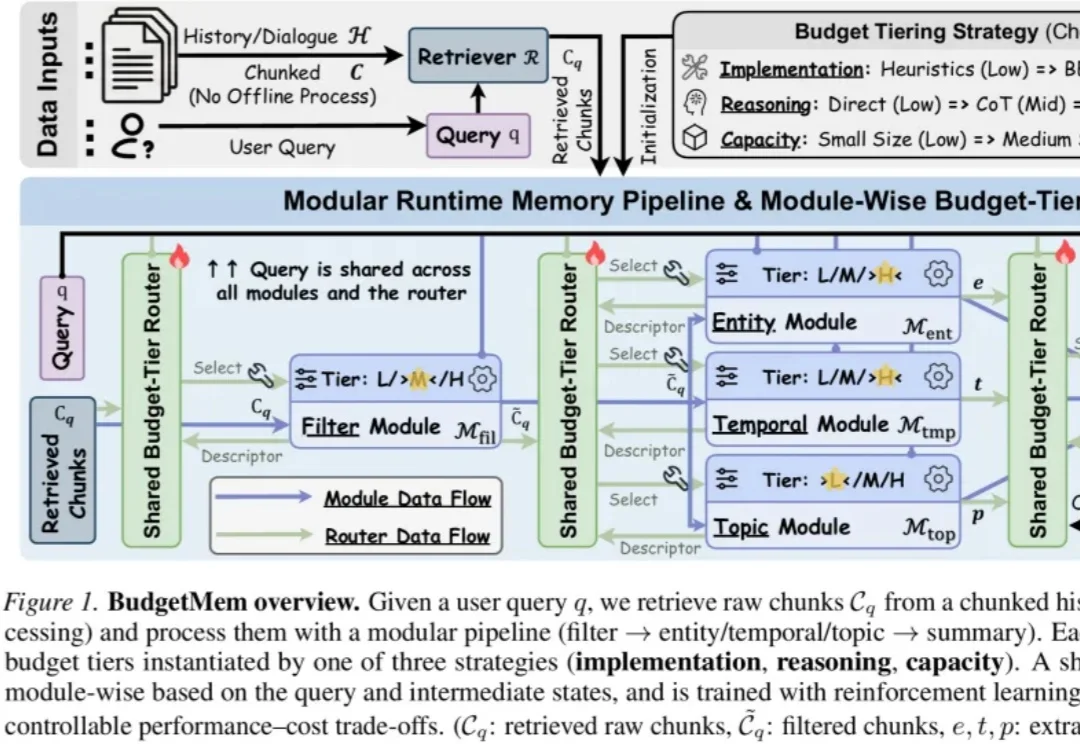
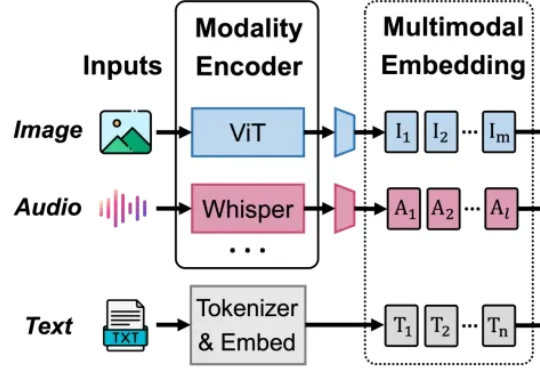
多模态大模型训练的显存与吞吐困局,被小红书开源的BigMac打破了BigMac 是原生多模场景下的流水并行训练新范式。它针对多模态大模型训练中计算效率与显存占用难以兼顾的问题,提出了依赖安全的嵌套流水线:以成熟的 LLM 流水线为主干,在不打乱 LLM 执行顺序的前提下,有序嵌入编码器和生成器计算,从而在不增加 LLM 流水线空泡、保持激活显存有界的同时,高效实现多模态流水训练。
来自主题: AI技术研报
8110 点击 2026-07-24 15:55